实验室4篇论文被AAAI 2024接收
发布时间:2023-12-09
近日,人工智能国际会议AAAI 2024公布录用结果,我实验室4篇论文被录用。AAAI会议全称为Annual AAAI Conference on Artificial Intelligence,由国际先进人工智能协会(Association for the Advancement of Artificial Intelligence, AAAI)举办,是CCF-A类推荐会议。本届AAAI 2024主赛道共有9862篇论文参与评审,录用2342篇,录用率23.75%。AAAI 2024将于2024年2月20日至27日在加拿大温哥华举办。
研究主题包括歌声合成、组合泛化、手语翻译和高效微调,录用论文的信息如下:
1. FT-GAN: Fine-grained Tune Modeling for Chinese Opera Synthesis
作者:Meizhen Zheng, Peng Bai, Xiaodong Shi, Xun Zhou, Yiting Yan
本文由我实验室2021级硕士生郑美镇同学和2021级博士生白鹏同学(共同一作),史晓东教授(通讯作者),2020级硕士生周巡同学,2022级硕士生严奕亭同学共同完成。
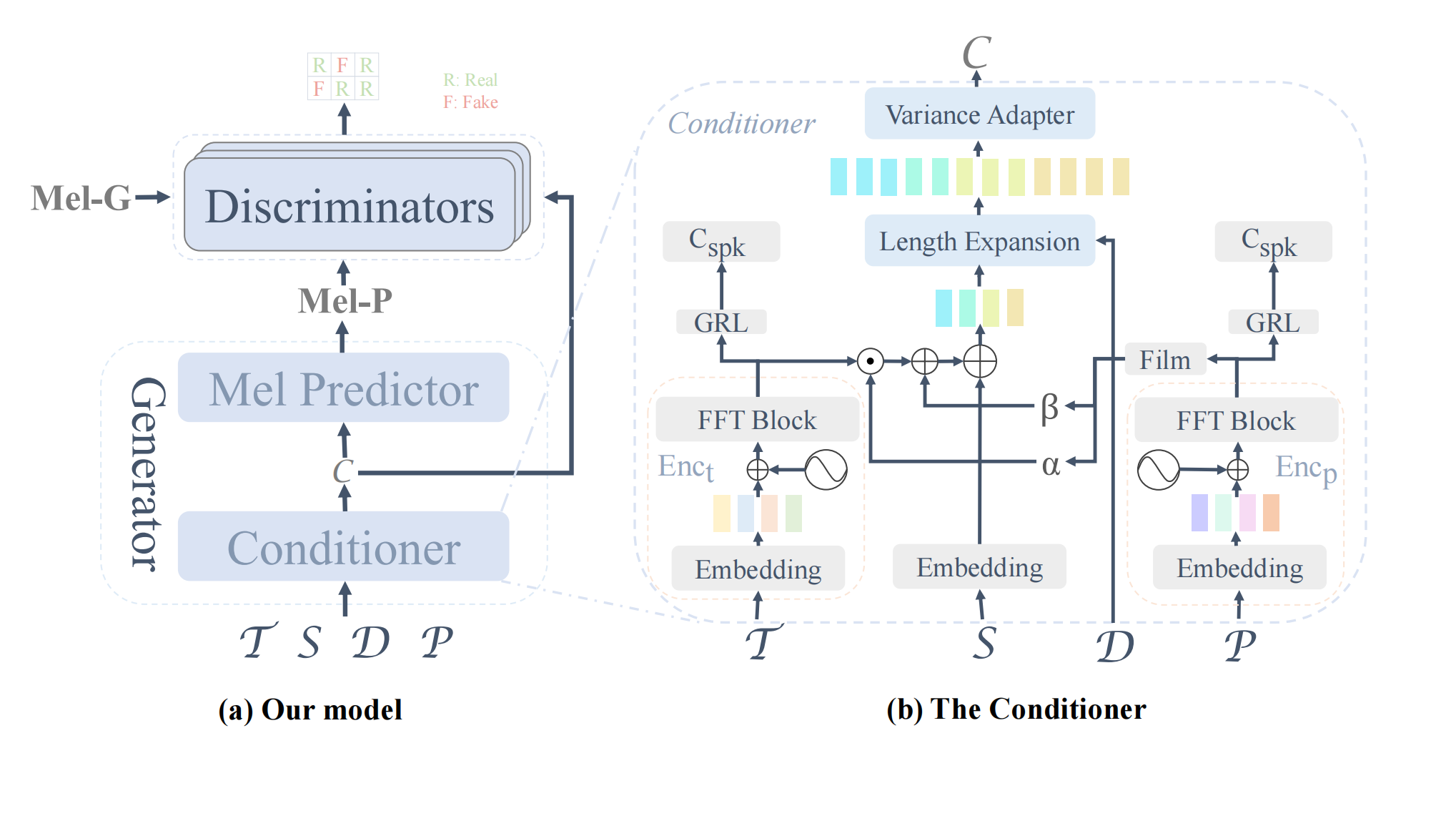
对话语音生成(Text To Speech, TTS)和歌声合成(Singing Voice Synthesis,SVS)一直是语音合成领域研究的热点,然而对于艺术性和复杂性更高的人声形式——戏曲合成的研究却十分匮乏,不管是从数据集角度还是模型角度。为了促进相关研究,本工作提出了一个高质量的歌仔戏音频-文本对齐数据集。数据集包含4.5个小时的歌仔戏(一种在闽南地区和台湾流行的戏曲,用闽南语演唱)清唱音频数据,音素标注和精确到0.01秒的时间对齐标注。针对戏曲音频的发音特点,本文提出了两种新的标注策略——元音变形和音高迁移,提升了合成效果。在模型方面,本工作在FastSpeech2的基础上加入了对抗训练,加入了一个额外的音高编码器,并在Mel Predictor部分使用Conformer架构,使得模型更加适配戏曲生成任务。工作进行了充分的实验,包括与SOTA模型的性能对比,对标注方法和模型结构的消融实验,以及在京剧合成任务上的表现。
2. Layer-wise Representation Fusion for Compositional Generalization
作者:Yafang Zheng, Lei Lin, Shuangtao Li, Yuxuan Yuan, Zhaohong Lai, Shan Liu, Biao Fu, Yidong Chen, Xiaodong Shi
本文由我实验室2021级硕士生郑雅芳同学和2020级硕士生林磊同学(共同一作),史晓东教授(通讯作者)等共同完成。
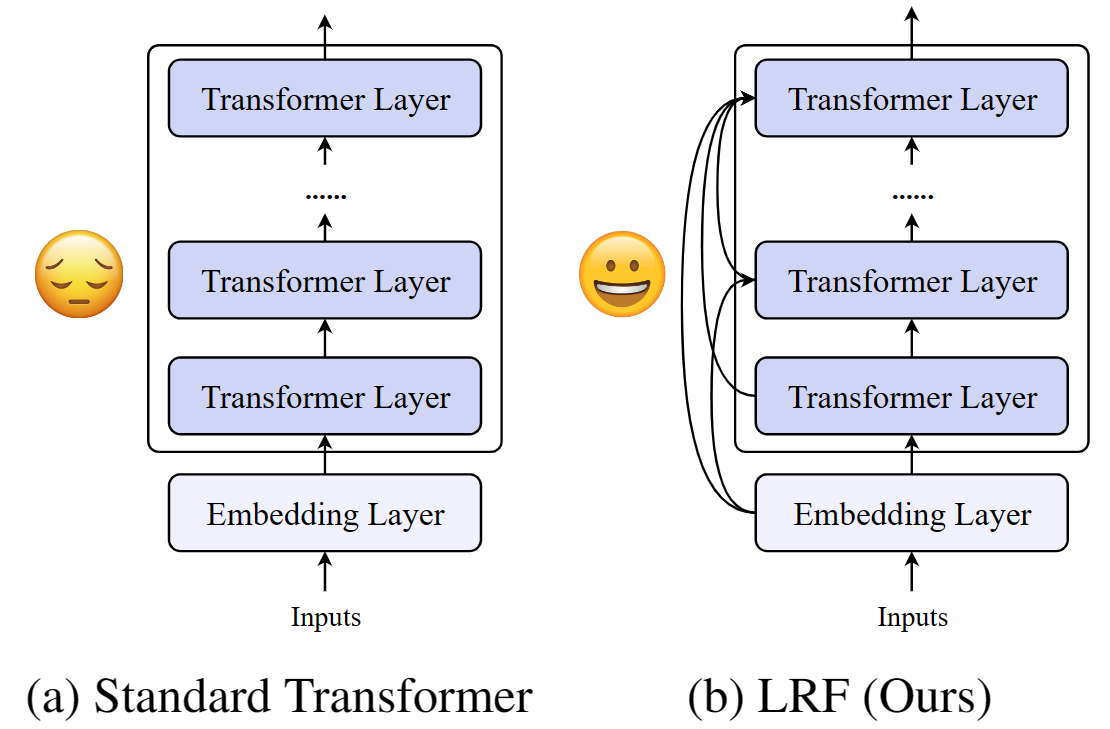

本工作研究文本序列生成任务中的组合泛化问题。现有神经网络模型难以处理组合泛化问题,即难以理解已知成分的未知组合。造成组合泛化问题的一个关键的原因在编码器和解码器的顶层表征中,语法表征和语义表征是耦合的,现有的工作专注于分离语法和语义的学习,而不是探索表征耦合问题的潜在原因。本工作分析了该问题的潜在原因,文章发现简单的通过残差连接在层之间传递信息难以合理的融合前面多层的信息,导致了层之间的信息遗忘,并进一步导致了表征耦合问题。鉴于上述问题,本工作提出逐层表征融合框架(Layer-wise Representation Fusion,LRF)用于解决组合泛化问题。该方法通过在Transformer的每个编码器和解码器层中引入一个融合注意力模块,使得模型在每个层高效的学习如何融合前置层的信息。本工作在语义解析和机器翻译的两个基准测试上进行实验,充分分析讨论了LRF在组合泛化问题上的表现,证明了框架的有效性。
3. Conditional Variational Autoencoder for Sign Language Translation with Cross-Modal Alignment
作者:Rui Zhao, Liang Zhang, Biao Fu, Cong Hu, Jinsong Su, Yidong Chen.
本文由我实验室2022级硕士生赵瑞同学,2021级硕士生胡聪同学,陈毅东教授(通讯作者),厦门大学数字媒体计算中心2023级博士生张亮同学(共同一作)和苏劲松教授合作完成。
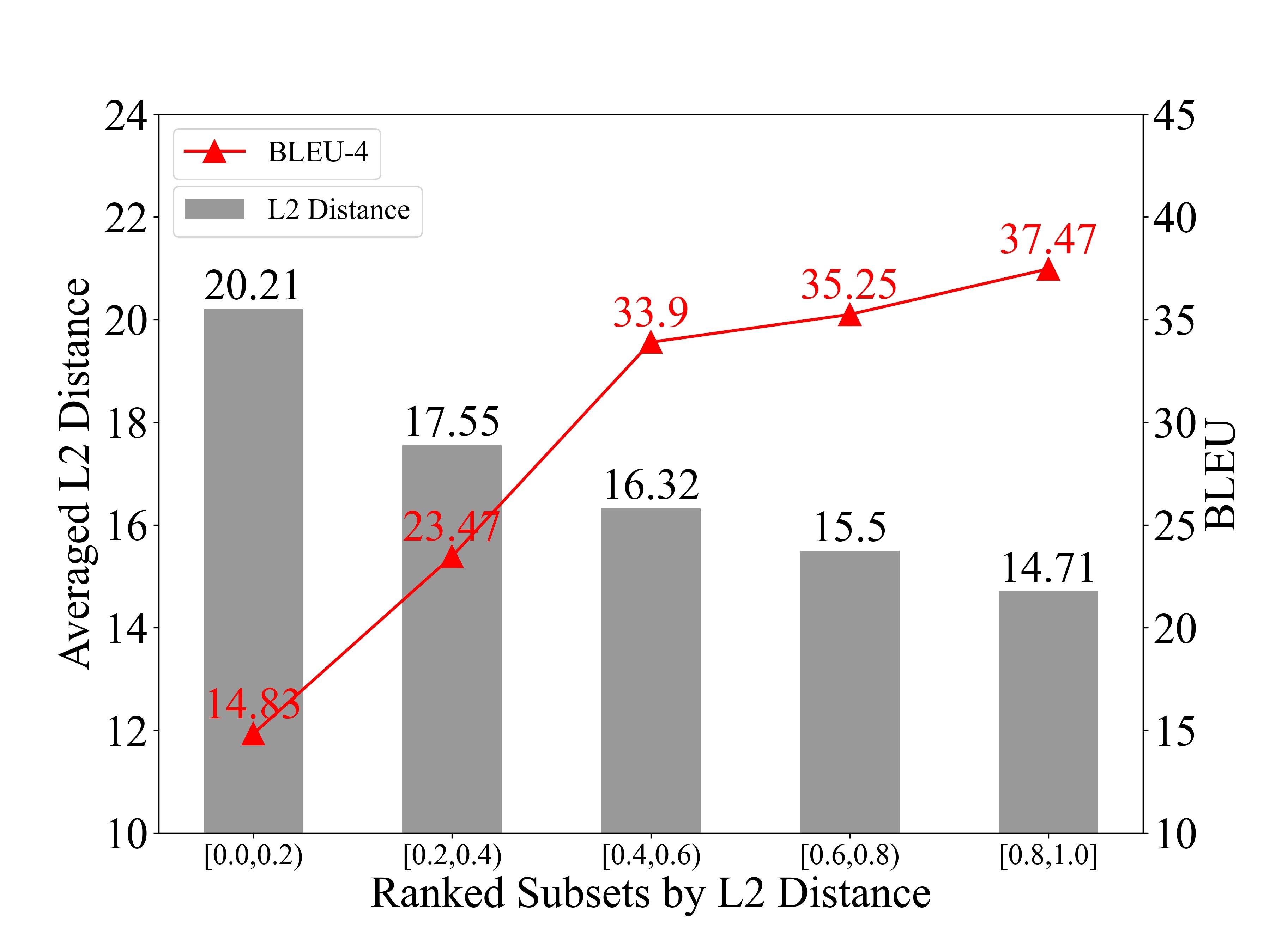
本工作研究手语翻译(Sign Language Translation, SLT)中的模态对齐问题。现有的手语翻译主要借鉴神经机器翻译的方法。然而,不同于普通的机器翻译任务,手语翻译任务接收视觉模态的手语视频作为输入,并且输出文本模态的目标句子。这种模态之间的差异限制现有手语翻译模型的性能。为了验证这一点,我们引导了一个先导实验。具体地,在实验中我们首先根据视觉特征与文本特征的L2距离将PHOENIX14T数据进行划分。最终我们发现典型的端到端手语翻译模型MMTLB在较大模态差异的子集中性能出现明显下降(如图1所示)。

为了有效地解决这个问题,本文提出一种基于条件变分自编码器(Conditional Variational Autoencoder,CVAE)的手语翻译框架CV-SLT。如图2所示,我们的CV-SLT包含两条路径:先验路径和后验路径。在先验路径中,模型只依赖视觉信息预测目标文本。在后验路径中,模型同时编码视觉信息和文本信息以重构目标文本。同时,我们使用了两个KL散度来对齐编码器与解码器的输出。本文在CSL-Daily和PHOENIX14T两个数据集进行了实验,分别取得28.94和29.27的BLUE分数(目前最高),这验证了模型的有效性。在消融实验中,本文进一步证明了提出的框架对模态对齐的促进作用。
4. G-Adapter: Towards Structure-Aware Parameter-Efficient Transfer Learning for Graph Transformer Networks
作者:Anchun Gui, Jinqiang Ye, Han Xiao
本文由我实验室2021级硕士生桂安春同学,2021级硕士生叶晋强同学,肖寒助理教授(通讯作者)共同完成。
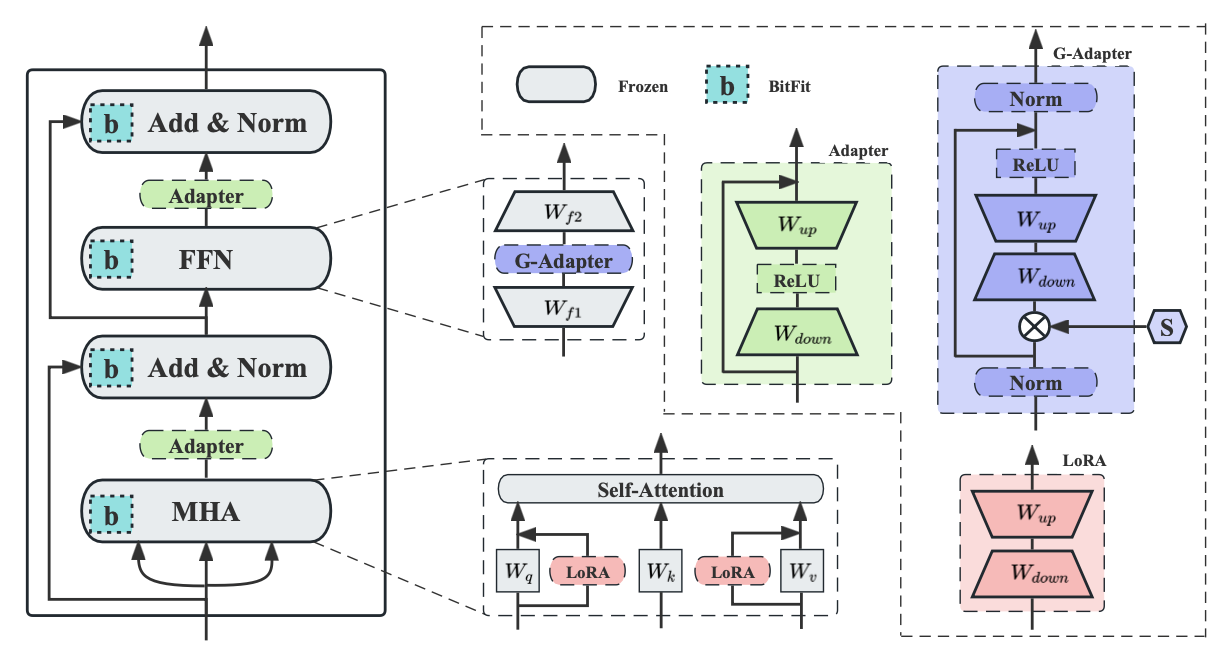
目前,参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)凭借其优异的性能和对计算资源的低消耗,已经成为一种流行的范式被应用于大规模预训练模型的迁移任务。然而,当前关于PEFT的研究往往集中在NLP和CV领域,并没有探索PEFT在图领域的可行性。考虑到基于Transformers架构的图模型已经展示了强大的图表征能力,本工作首次全面地研究了将现有NLP领域下的PEFT方法直接迁移到图模型的不足和局限性(比如:特征分布偏移)。为了缓解这些问题,本工作提出了一种面向图结构的参数高效微调框架,通过在设计的GCN微调模块中引入图结构的先验信息,有效地增强了模型的图表征能力。本工作在9个公开数据集上进行了广泛实验,结果表明该方法取得了更好的性能相比于其他基线方法。