实验室3篇论文被ACL 2026接收
发布时间:2026-04-07
近日,我实验室3篇论文被第64届国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称ACL)主会录用。ACL是计算语言学和自然语言处理领域国际排名第一的顶级学术会议,由国际计算语言学协会组织,在中国计算机学会(CCF)推荐会议列表中被列为 A 类会议。会议每年召开一次,今年将于2026年7月2日至7日在美国加利福尼亚州圣地亚哥市举办。
本届会议共收到12148篇有效投稿,主会录用率为18%,我实验室录用论文的相关信息如下:
1. Translation with Thought: Difficulty-Adaptive Reasoning via Reinforcement Learning for Multi-Domain Machine Translation
作者:Yongshi Ye, Biao Fu, Chongxuan Huang, Yidong Chen, Xiaodong Shi*
该文由我实验室2024级硕士生叶咏诗、黄崇轩,2023级博士生付彪,陈毅东教授,史晓东教授(通讯作者)共同完成。
论文介绍:
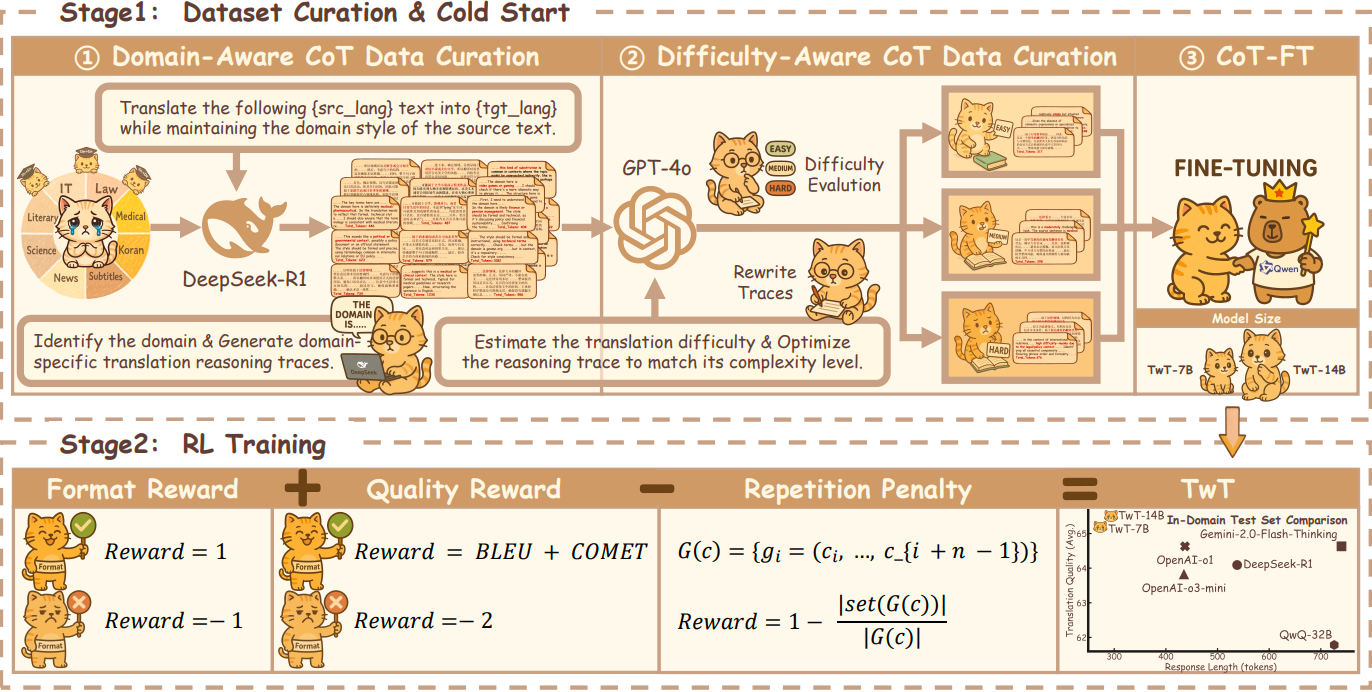
针对多领域机器翻译中不同领域术语、句法和风格差异显著,且输入难度不均衡的问题,本文提出TwT(Translation with Thought)框架,使模型能够在快速直觉式翻译与深度审慎式推理之间自适应切换。具体而言,TwT首先对由DeepSeek-R1蒸馏得到的长链式翻译推理数据进行难度感知重写,并通过监督微调学习与输入复杂度匹配的推理模式;随后结合翻译质量奖励与重复惩罚开展GRPO训练,进一步兼顾翻译准确性与推理效率。实验在15个基准、域内与域外场景以及多种已见和未见语言上验证了该方法的有效性。结果表明,TwT在保持或超过现有大推理模型翻译性能的同时,可将推理token开销降低32%–60%,展现出良好的跨领域泛化能力与高效推理能力。
2. CNSL-bench: Benchmarking the Sign Language Understanding Capabilities of MLLMs on Chinese National Sign Language
作者:Rui Zhao, Xuewen Zhong, Xiaoyun Zheng, Jinsong Su and Yidong Chen*
该文由我实验室2025级博士生赵瑞,2024级硕士生钟雪文、郑小云,厦门大学数字媒体计算中心苏劲松教授,陈毅东教授(通讯作者)共同完成。
论文介绍:
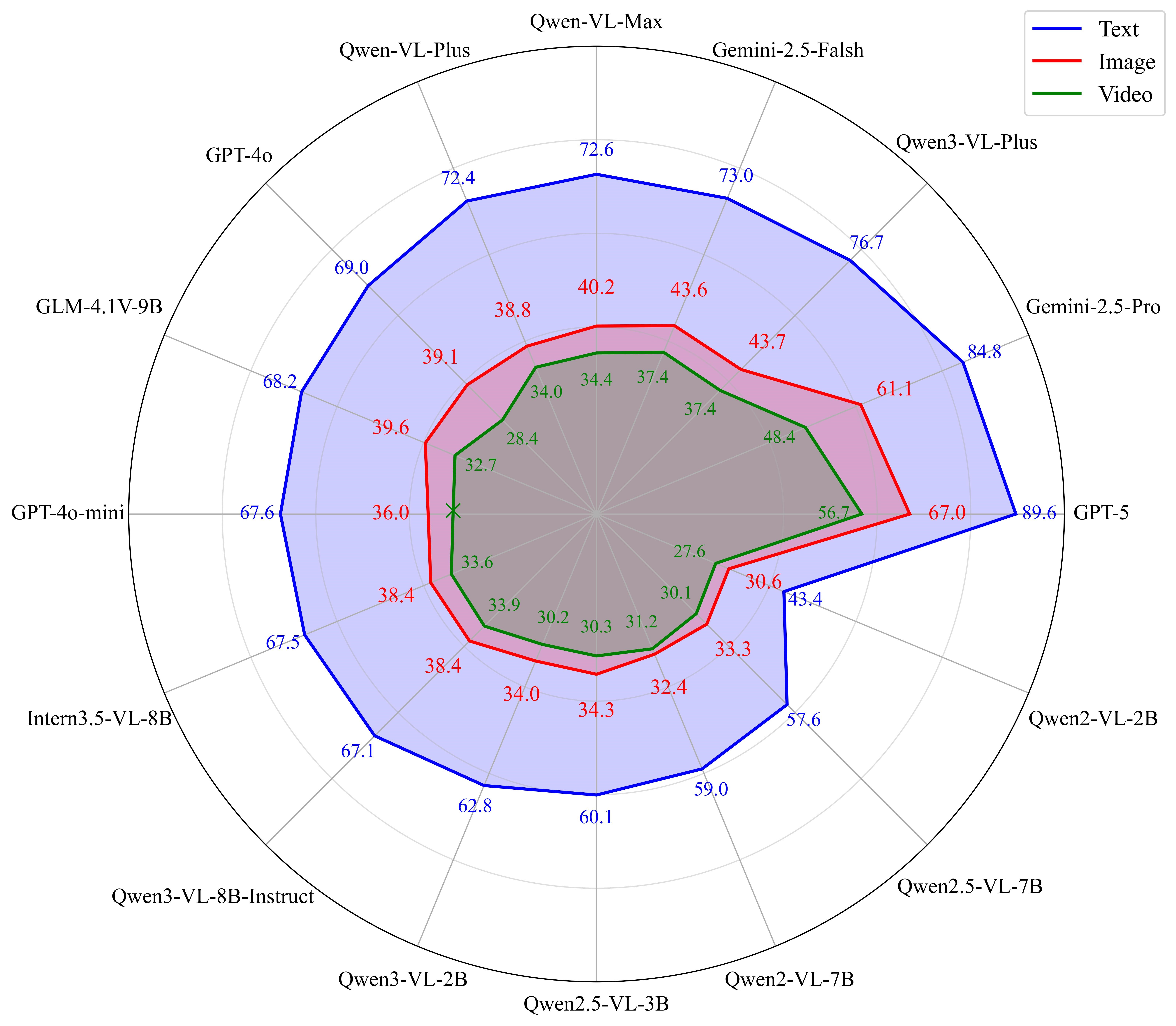
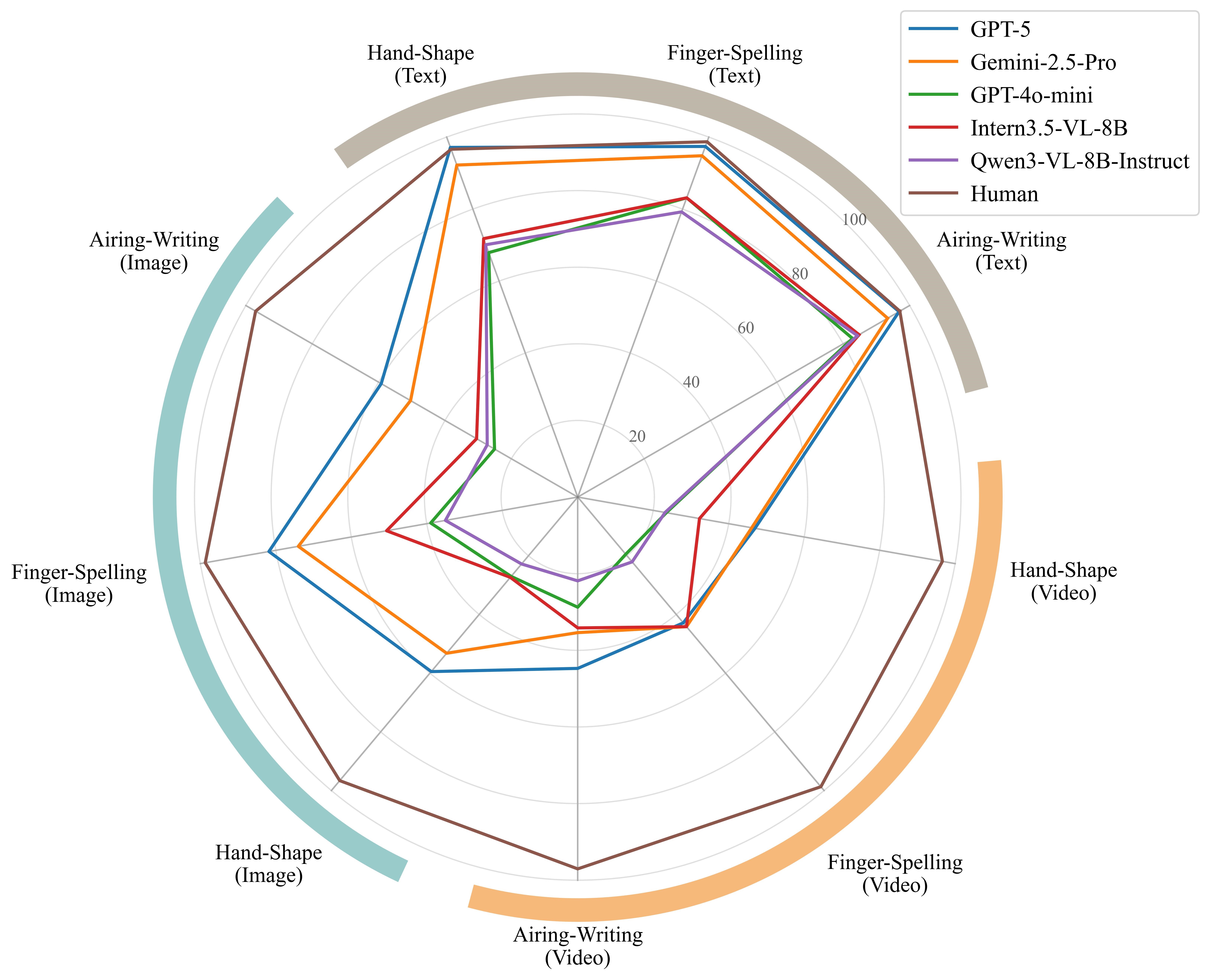
针对当前多模态大模型在手语理解方面缺乏系统评测基准的问题,本文提出了首个面向中国国家通用手语的多模态理解基准 CNSL-bench。该基准以《中国国家通用手语词典》为语义基础,在此之上对齐构建了文本描述、示意图像和手语视频三种模态,并进一步标注了空书、指拼和指式等关键手语构形,用于细粒度分析模型的真实理解能力。最终,CNSL-bench 由 6,707个标准手语条目扩展形成 20,121个评测样本,为手语理解提供了统一、可控且可复现的评测平台。基于该基准,本文系统评测了 21个多模态大模型。实验结果表明,尽管当前多模态大模型在通用视觉语言任务上取得了显著进展,但在手语理解上仍与人类存在明显差距,尤其在图像和视频模态下表现更弱;同时,不同手语构形之间也存在显著性能差异,模型对指拼类样本相对更敏感,而对空书和手指字母类样本的理解能力仍较为有限。进一步分析还发现,链式推理等测试时扩展策略并不能从根本上弥补这一不足,说明当前模型在手语的时序建模、视觉语义对齐和指令遵循等方面仍面临挑战。该工作为多模态大模型的手语理解能力评测提供了首个系统性基准,也为后续构建更鲁棒、更具人类对齐能力的手语智能系统奠定了基础。
3. Selective Contrastive Learning For Gloss Free Sign Language Translation
作者:Changhao Lai+, Rui Zhao+, Xuewen Zhong, Jinsong Su and Yidong Chen*
该文由我实验室2023级硕士生赖昌豪,2025级博士生赵瑞(共同一作),2024级硕士生钟雪文,厦门大学数字媒体计算中心苏劲松教授,陈毅东教授(通讯作者)共同完成。
论文介绍:
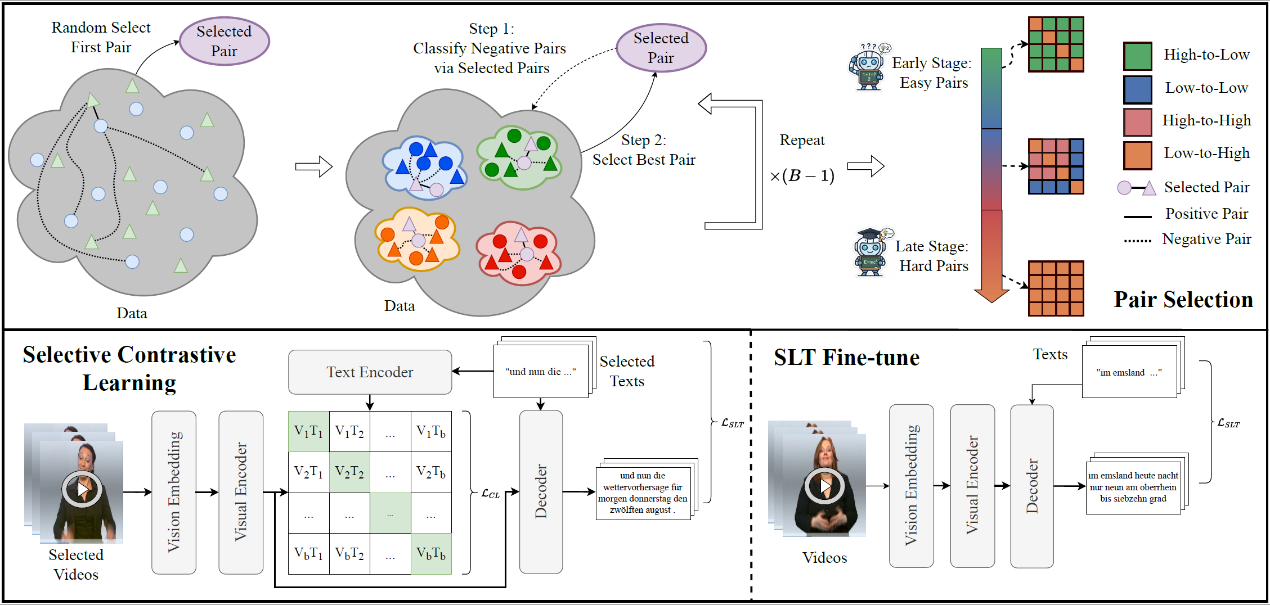
在无词汇标注的手语翻译任务中,现有系统常采用视觉-语言预训练进行跨模态对齐,但其随机批次内的“负样本”对比往往会错误地将语义相似甚至相同的视频-文本对当作互相排斥的样本,从而引入嘈杂的监督信号并阻碍可靠的模型对齐 。研究表明,不同负样本对模型的贡献极不均衡,仅有少部分能提供有效且持续的对比信息 。针对此问题,本文提出了一种选择性对比学习框架(SCL-SLT),其核心是基于课程学习的样本对选择策略 。在训练时,模型首先利用参考模型计算出候选负样本的相似度动态变化轨迹,并以此进行打分和分类 。在构建训练批次时,该策略遵循从“简单样本”逐渐过渡到“困难样本”的渐进式原则,优先挑选高信息量的负样本来强化对比监督,有效降低了无效或错误负样本的干扰 。在利用筛选出的优质样本完成视觉和文本模态的精准对齐后,框架进入翻译微调阶段,此时辅助的文本编码器被分离,模型仅依靠翻译目标损失进行端到端的生成优化 。这种纯粹以数据为中心的方法无需额外的模块或复杂的外部标注,仅通过最大化数据的内在对比价值,便在主流基准数据集上实现了最优的翻译精度 。